

12月8日,美团LongCat团队正式发布并开源LongCat-Image图像生成模型。这款仅6B参数的模型,凭借同源架构与渐进式学习策略,在文生图和图像编辑领域实现性能突破,部分能力已逼近大尺寸头部模型。

来源网络
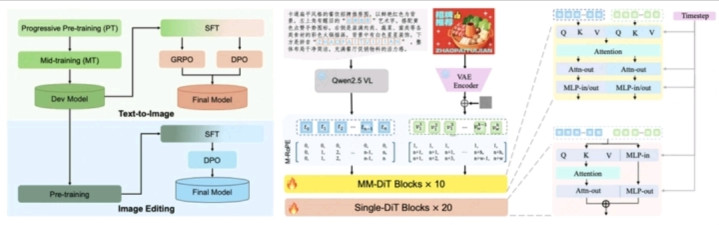
模型采用文生图与图像编辑同源架构,搭配渐进式学习策略,在紧凑参数下达成指令遵循精准度、生图质量与文字渲染能力的协同提升,尤其在单图编辑可控性和汉字生成覆盖度上优势显著。图像编辑领域,其在GEdit-Bench、ImgEdit-Bench等测试中斩获开源SOTA成绩。模型以文生图Mid-training版本初始化,搭载多任务联合学习机制,结合预训练多源数据、SFT人工精标数据,实现指令遵循精准度、泛化性与视觉一致性的同步进阶。
中文文字生成是模型核心亮点,针对行业中文渲染痛点,搭建三层课程学习体系。预训练阶段依托千万级合成数据,实现通用规范汉字表8105个汉字全覆盖;SFT阶段引入真实文本图像,提升字体排版适配性;RL阶段融合OCR与美学双奖励模型,兼顾准确性与融合度。同时采用字符级编码,降低记忆负担,可支撑海报、对联、门店招牌等场景的复杂及生僻字渲染。
来源网络
为提升出图真实感,模型构建数据筛选与对抗训练框架。预训练和中期训练剔除AIGC数据,规避“塑料感”纹理;SFT阶段人工精筛数据对齐大众审美;RL阶段引入AIGC检测器作奖励模型,引导学习真实物理纹理与光影质感,大幅提升图像真实度。
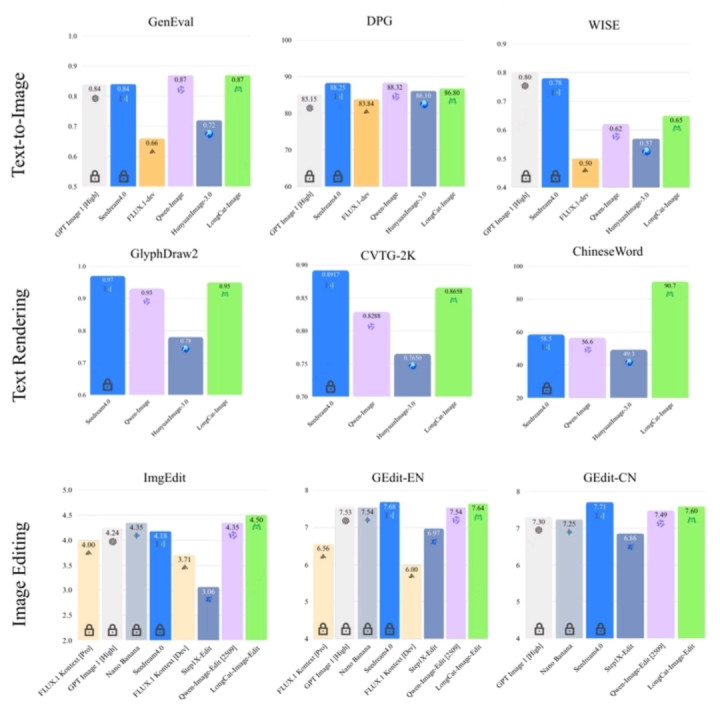
客观测试验证模型实力,图像编辑任务中,ImgEdit-Bench得分4.50分、GEdit-Bench中英文7.60/7.64分,居开源首位且逼近闭源模型;文字渲染ChineseWord评测90.7分,领先同类模型;文生图任务GenEval 0.87分、DPG-Bench 86.8分,具备强竞争力。
来源网络
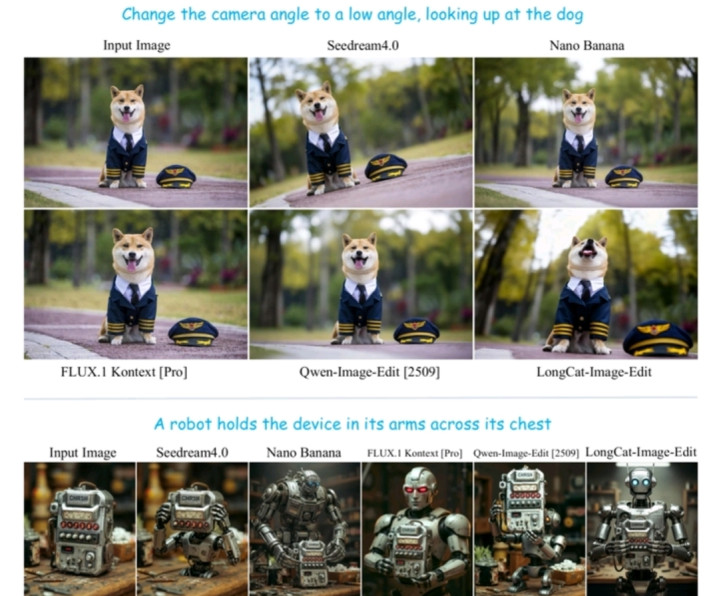
主观评测方面,文生图采用MOS评分,模型在真实度上优于主流模型,文本-图像对齐达开源SOTA;图像编辑用SBS对比评估,虽与Nano Banana等商业模型有差距,但显著超越其他开源方案,成开源领域优选。
团队已全面开源多阶段文生图与图像编辑模型,可适配从科研到商业的全流程需求,同时升级LongCat APP,新增24个零门槛模板,降低普通用户操作难度。
小参数也能实现高性能突破。LongCat-Image以6B参数达成多维度跃升,打破大参数即高性能的行业认知,为算力受限的中小开发者与企业提供轻量化选择,降低AI视觉生成技术应用门槛。

来源网络
中文优化是国产模型核心竞争力。专项优化精准命中本土需求,解决中文渲染痛点,为电商海报、国风设计等场景提供技术支撑,体现国产模型本土化优势,开辟差异化竞争赛道。
开源模式加速技术生态迭代。美团全量开源模型工具,让成果惠及开发者社区,汇聚行业智慧推动技术迭代,同时为自身积累场景反馈,形成研发正向循环,实现企业与行业共赢。
技术创新需兼顾体验与实用。模型在追性能指标时,通过人工精筛数据、美学奖励模型对齐大众审美,贴合用户实际需求,规避“唯参数论”误区,为行业提供务实研发范式。
来源网络
AI模型的价值,不在参数大小,而在解决需求的精准度。LongCat-Image的开源是国产AI技术进阶的缩影,也是技术普惠的实践。小参数高性能证明创新核心在架构与适配,中文优化展现本土需求洞察,开源模式筑牢生态根基。未来AI竞争是技术、适配与协同能力的综合较量。你认为该模型能在哪些场景发挥价值?可在评论区分享看法。
网上配资知识网首选提示:文章来自网络,不代表本站观点。



